TL;DR Large Language Models (LLM) are used as agents to drive pre-surgery questionnaires
Pre-surgery questionnaires — why do we need them?
Pre-surgery questionnaires collect detailed health histories before surgical procedures. They identify potential risks, including allergies, underlying conditions, or previous reactions to anaesthesia. While historically paper-based, electronic formats are increasingly used. Despite Electronic Health Records adoption, significant information gaps regarding patient history persist, necessitating questionnaires before surgery.
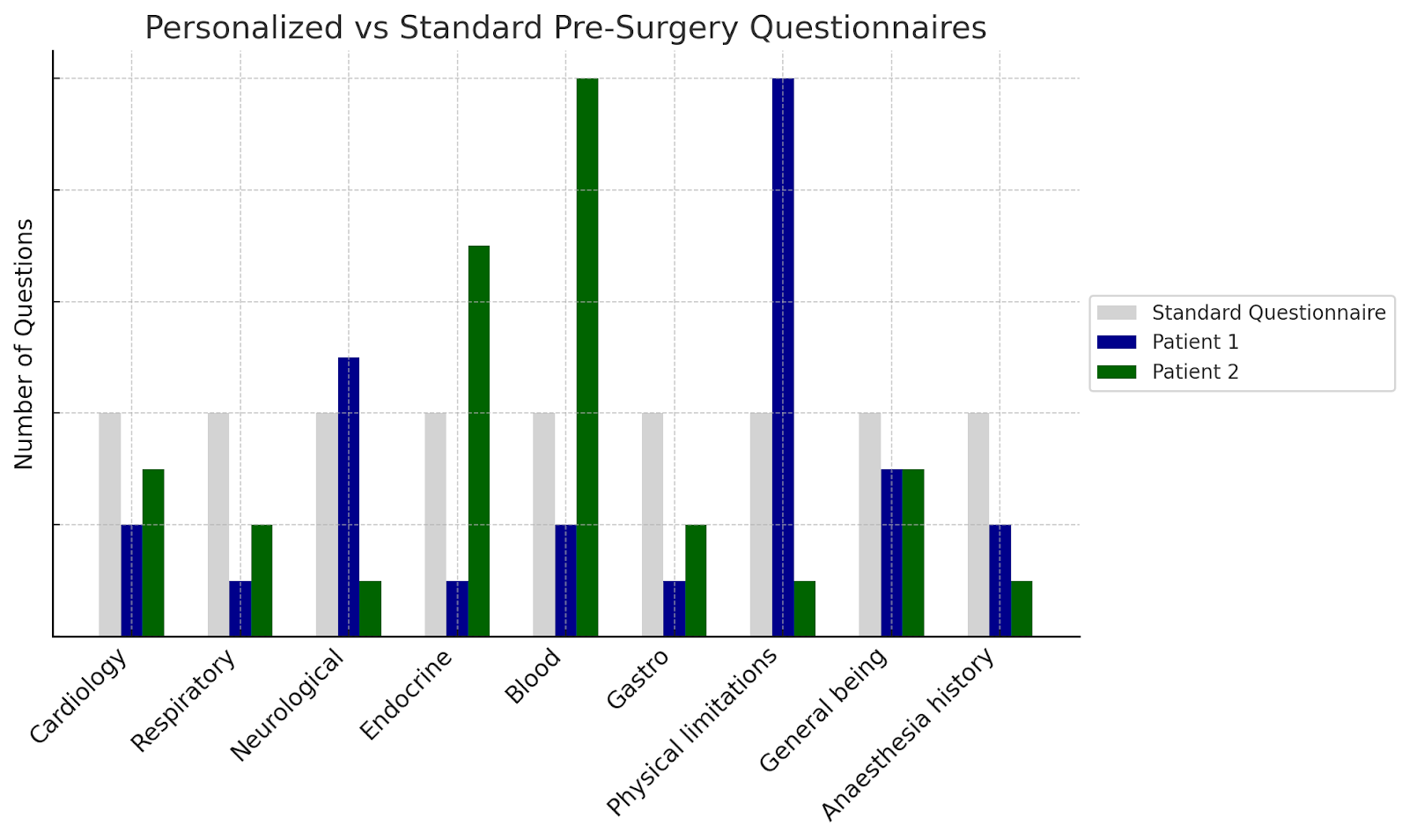
Many questions, shallow information
Pre-surgery questionnaires often require numerous questions across various organs and symptoms, leading to patient fatigue and incomplete responses. Electronic questionnaires improve the process through rules-based question selection, such as triggering follow-ups based on responses. However, this approach only works for simple scenarios, and extensive questions remain necessary to cover all potential risks.
Personalised questionnaires — more information, less questions
Each patient possesses different histories, conditions, and treatment plans. Research aims to personalize questionnaires by intelligently determining essential questions for each patient. The system recognizes when follow-up questions are needed for detailed information and when sufficient data exist, balancing thoroughness with efficiency.
Limitations of LLMs
While LLMs offer promise for enhancing pre-surgery questionnaire efficiency, they have notable limitations. A significant limitation is their “single-mindedness” — LLMs function as single streams of token completion, similar to single-threaded applications. They struggle with multitasking or simultaneous role-taking. Experiments revealed that while LLMs could select appropriate questions from lists, they often failed when also needing to evaluate which clinical areas had sufficient coverage and which required further inquiry.
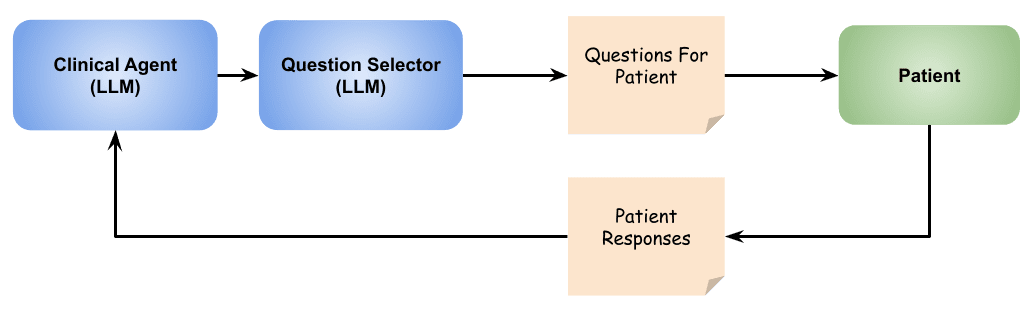
Using agentic flow
LLM agents, where multiple LLMs work together coordinately, offer promising approaches for implementing complex flows with specialized roles. Implementation includes a “clinical agent” responsible for understanding and evaluating patient medical history, and a “question selector” focusing on choosing relevant questions from given lists. This approach enables effective multitasking, ensuring thoroughness and efficiency.
Leveraging LLM knowledge with guardrails
Large language models, trained on extensive datasets including medical literature, possess valuable knowledge for analyzing patient responses and generating relevant follow-ups. Some LLMs demonstrate significant medication knowledge and can infer underlying health conditions from patient medication lists. External tools, such as medication database queries, provide additional context. However, this relies on a critical assumption: that LLMs correctly interpret and apply data — not trivial in clinical settings.
One implemented guardrail allows agents to select from predetermined questions rather than creating new ones. This ensures clinician-defined wording remains exact, as small grammatical changes may alter clinical meaning. For example, “discomfort when exercising” differs clinically from “chest pain during physical activity.” Limiting agents to predetermined questions preserves clinical meaning and precision.
Following a semi-structured process
Clinical agents can be prompted to operate in phases, beginning with specified questions, then exploring additional areas based on responses. Business rules can guide the process — avoiding certain questions, preventing repetition, or limiting questionnaire length. Retrieval Augmented Generation (RAG) techniques guide exploration using relevant content like hospital guidelines or research literature.
Understanding ‘performance’
Evaluating agentic questionnaires should focus on ensuring they collect essential clinical information. Key objectives include: asking important, relevant questions from existing questionnaires; avoiding irrelevant questions to save time; and introducing new questions based on patient responses for additional insights.
Performance metrics include:
- Compliance (% of essential questions asked)
- Coverage (% of health issues uncovered)
- Waste (% of irrelevant questions asked)
- Efficiency (number of questions versus standard questionnaires)
Implementing within a clinical application
Functionality was implemented in the existing perioperative application Patient Optimizer (POP), leveraging familiar clinician interfaces for reviews and feedback. Clinical input refined logic, question relevance, and user experience. Iterative design optimized the system for real-world use, differentiating clinical language for clinicians from simplified summaries for patients. Displaying agent output to clinicians provided insight into question selection reasoning and improvement opportunities.
Opportunity to collaborate
This demonstration shows agentic workflows’ real-world clinical application and potential for improving and streamlining processes. This approach proves useful in scenarios where process efficiency and flexibility matter significantly. Readers are invited to share experiences with agentic workflows or explore collaboration opportunities.